
写在前面
最近在研究一些nosql数据库,看了些数据库的设计原理,就想着能不能自己设计实现个小型的nosql数据库,自己玩玩也好,可以长期专注这个,同时还能锻炼自己的开发能力;
一直觉得学习技术,一定要自己动手做一遍,不然就成了纸上谈兵,光说不练假把式了;但是自己又不想是直接照抄别人的思路去再实现走一遍,自己写的代码怎么也得有点自己的思考吧。本文就是记录自己herDB的设计思考:
哈希表
首先看张网上的hashmap的数据结构图: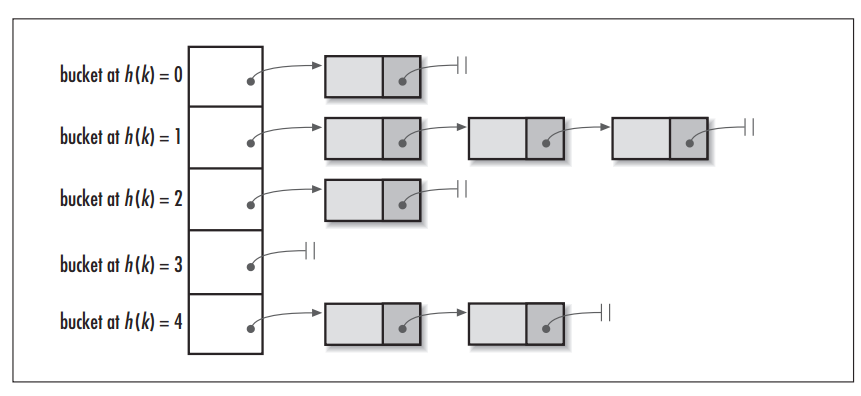
hashmap 是通过hash函数,将key/value中的key提取出特征指纹,只是这个特征是用数字表示的而已,然后根据特征值放在事先定义好的bucket中;如果bucket里已有其他数据(俗称碰撞)可以通过链表的形式存储碰撞项。
java的hashmap就是通过定义好的一定长度(一般为2^n)的数组充当bucket,通过hash值 &(bucket的长度-1)作为数组的index;
- hashmap很关键的一步是要找到一个合适的hash函数,能够尽量提取数据key的不同于其他的特征值来, 以避免碰撞;
- 如果碰撞过多,链表的长度就会很大,这个时候查询就会慢很多,优化的策略是java8里将过多的碰撞改用红黑树或btree的数据结构存储
设计思路:
hashmap在内存里可以通过数组的形式组织实现,但是在磁盘里该用怎么样的结构去实现hash数据结构,所以一些实现了hashmap的nosql一般是通过在文件头写入固定数量的Bucket,如HashDB: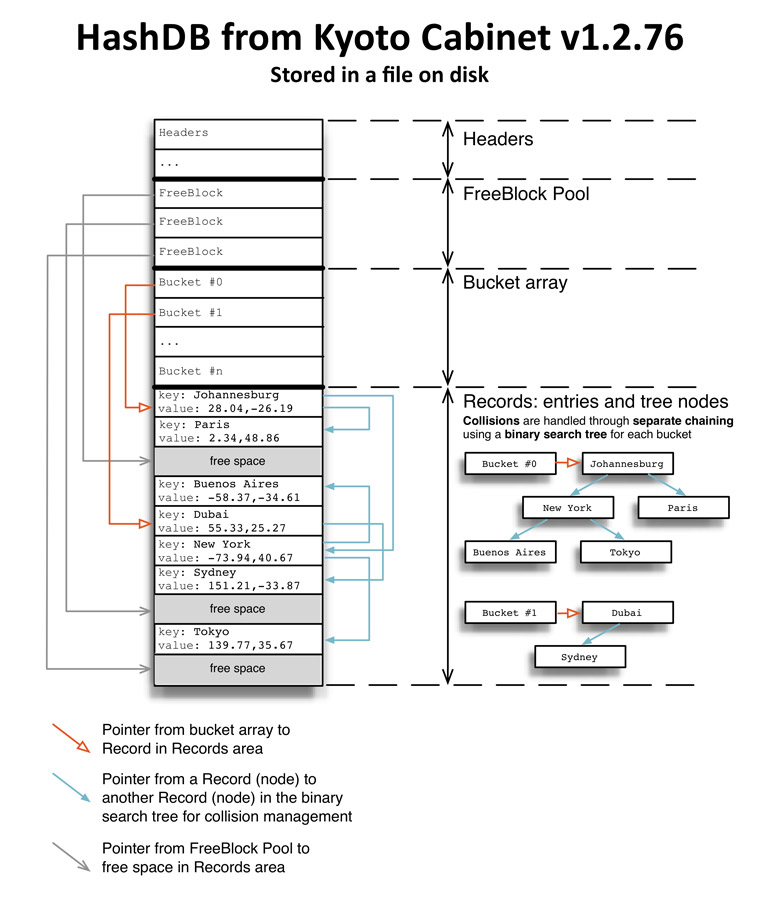
- 这样做的缺点是:
- 不能很好的实现扩容,只能是固定数量的bucket,这样子会造成随着数据的增多,碰撞会越来越大,性能就会越来越差;
- get操作的时候会先磁盘读取bucket, 然后才会定位到相应的数据(>=1次的磁盘读取),这样最少都要两次的磁盘读取才能定位到相应的数据,有没有最少可以一次定位到数据的实现呢?
为此自己实现了herDB小玩具,画了张示意图: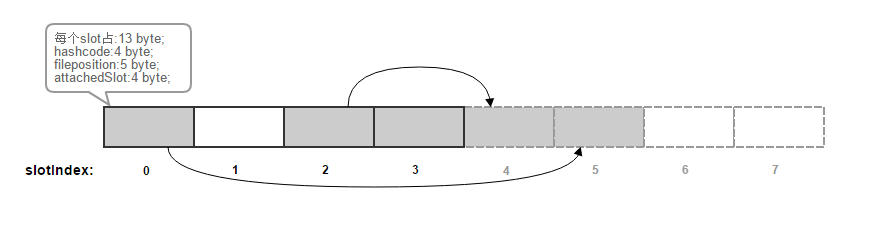
- 每个slot(固定大小13B)仅仅可以存放一个key/value键值对,阴影的部分代表已经为被占据的slot,每次get put操作之前都会将该索引文件全部加载到内存里;
- slot的被分为两个部分,实线部分相当于buckts,而虚线部分负责存放冲突的key/value,两者的数量相等,当虚线部分已经满的时候就该resize了;
- 每个slot由 key的hashcode + 磁盘rawdata的文件偏移数 + 链接的下一个slot的index数 三个组成,每个slot可以当成是一个真实key/value的代表,相关操作:
- put(key, value)操作:key通过hash函数得到h;
h & (实线slots.length - 1)得到实线slots的index,然后找到可以存放的slot;每一碰撞都顺序取虚线部分的slot;- get(key, value)操作:key通过和put一样的hash过程得到实线部分的slot index,通过链的查找得到数据的offset,继而得到key/value的相关数据;
- 每次完成操作后都将该内存数据直接全部flush到磁盘文件中,在下次打开的时候,将从.index文件中readFully全部数据,相当于将磁盘文件每13B分割成一个slot;
磁盘数据文件的格式为: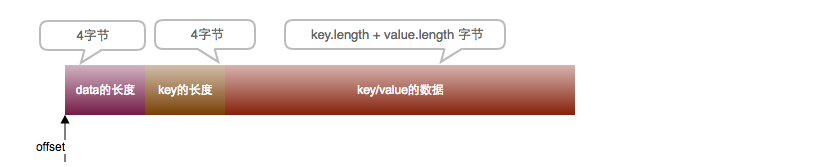
data的长度数为:4(key的长度数) + key.length + value.length, get操作的时候通过索引获取到的offset,先随机读取将文件指针置于offset的位置,然后顺序读取data的长度;再通过读取key长度的字节获取key,读取剩余的字节为value的数据;
在进行如下的添加操作后:
索引数据与磁盘的原始数据可能如下图: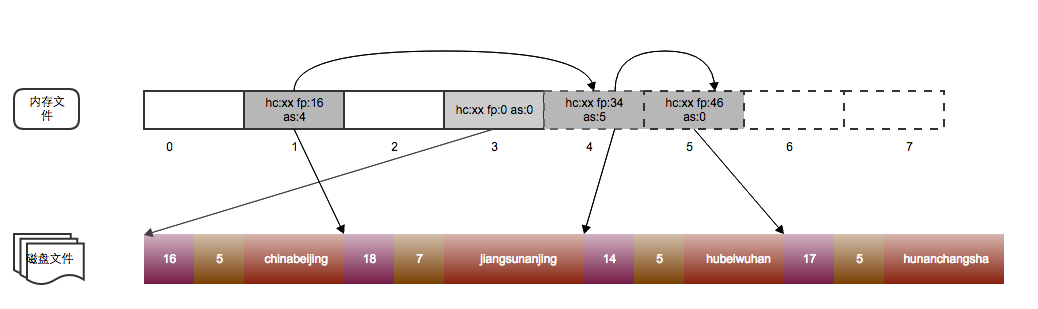
读取的时候,比如:
先将key “hunan”经hash函数得到h,通过另外的hash算法得到key的hashcode,这里的hashcode计算方法不是之前那个hash函数,在这实现里只是通过如下计算得出;
再 h & (4 - 1)得到slot的index,得到index = 1,依次查询其冲突链上的数据,比对hashcode,hashcode不一致查找的数据必定不是该slot代表的数据;
但是hashcode相等的情况下也要比较下key的原始数据,因为在一些很少的情况下会出现hashcode一致但是对应的key真是数据不同;
最终可以得到”huanan”对应的数据:”changsha”
一些改进:
- 扩容方面:
- 由于一次性将index文件全部读入内容,可以很好的实现扩容,通只需要将索引内存数组 * 2得到一个新的内存数组,经过顺序读取数据文件的每个key/value,
在新的内存索引数组里重新生成新的索引数据;- 扩容的时候,为了优化磁盘读取,分别添加了读缓存与写缓存;
- 多线程方面:
学习concurrenthashmap的分段锁的机制,实现了多线程的分段锁并发操作,就是简单地将hash表操作先经一次hash 然后对indexSegments.length - 1取余得到对应的indexSegment;
然后仅对该indexSegment加锁,这样子就可以避免对整个索引加锁;如下图所示:
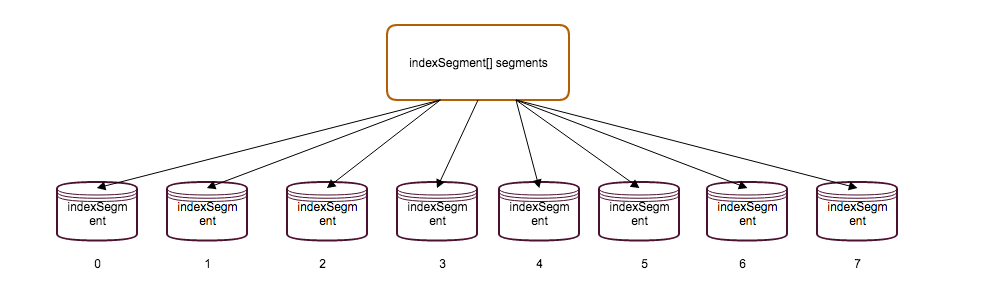
附代码地址https://github.com/funeyu/herDB